
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- permisision부여
- relu
- 셀리니움
- sellenium
- 광주인공지능학원
- 광주국비지원학원
- 활성화함수
- 댓글분석
- 유투브크롤링
- 머신러닝
- 스마트인재개발원
- CountVectorizer
- jsp
- DataFrame
- 과대적합
- 인공지능학원
- python
- 크롤링
- tfidf
- 자바
- 파이썬
- servlet
- 과대적합제어
- Selenium
- iris붓꽃
- 토큰화
- 웹크롤링
- 인공지능
- 데이터프레임
- 딥러닝
- Today
- Total
+ Hello +
[스마트인재개발원] [머신러닝] 네이버 영화 리뷰 분석하기 본문

* jupyer에서 Kkma 사용하기 위해 자바에서 가져오기
- 파이썬 버전 확인
!python --version- pip 업그레이드
!pip install --upgrade pip- Kkma import 작업해주기
!python --version
!pip install --upgrade pip
!pip install JPype1-1.1.2-cp38-cp38-win_amd64.whl
!pip install konlpy
from konlpy.tag import Kkma
kkma = Kkma()1. 리뷰 파일 불러오기
- pandas import 작업
import pandas as pd1) 파일 불러와서 10개 항목 확인하기
df_train = pd.read_csv('nsmc-master/ratings_train.txt', delimiter='\t')
df_train.head(10)
2-1) train 결측치 제거하기
- 결측치 확인
df_train.info()
-> 5개의 결측치 존재
- 결측치 제거
- .dropna : 결측값있는 행 제거
df_train.dropna(inplace=True)2-2) test값 결측치 제거하기
- test 파일 불러오기
df_test = pd.read_csv('nsmc-master/ratings_test.txt', delimiter='\t')- 결측치 확인 : .info()
df_test.info()
--> 결측치 3개 확인
- test 결측치 제거
df_test.dropna(inplace=True)
3) tfidf를 통해 학습
- import 작업
from sklearn.feature_extraction.text import TfidfVectorizer# tfidf를 통해서 판단
tfidf = TfidfVectorizer()
# 3개만 학습시켜보기
tfidf.fit(X_train[:3])- 3개의 댓글 확인
X_train[:3]
4-1) 띄어쓰기 기준으로 토큰화 하여 단어사진 확인
tfidf.vocabulary_
** Kkma를 통해 토큰화
:: kkma ::
- 토큰화를 조금 더 유기적으로 해줌(한글에 맞게)
- kkma 토큰화 방법 총 3가지 있음
1) 문장 단위 토큰화 : sentences()
2) 명사 단위 토큰화 : nouns()
3) 형태소 단위 토큰화 : morphs()
- 원래 문장

4-2) Kkma으로 명사 단위 토큰화 : .nouns()
kkma.nouns(X_train[0])
4-3) Kkma으로 형태소 단위 토큰화 : .morphs()

- .pos : 나뉜 형태소가 어떤걸 의미하는지 적혀있음

형태소의 의미알려주는 사이트
http://kkma.snu.ac.kr/documents/?doc=postag
- 감성분석할 때는 동사나 형용사만 가져오면 됨
- dataframe 형태로 만들어주기
d =pd.DataFrame(kkma.pos(X_train[0]), columns=['morphs','tag'])
# index를 tag 컬럼으로 바꿈
d.set_index('tag',inplace=True)
# tag가 vv랑 nng인 값만 출력되게
d.loc[['VV','NNG']]
5) tfidf의 토큰화 방법 변경
5-1) 명사 단위로 추출하는 토큰화 함수 만들기
def myTockenizer(text):
return kkma.nouns(text)- tfidf에 내가 만든 토큰 함수 적용
tfidf = TfidfVectorizer(tokenizer = myTockenizer)- 3문장만 추출하여 단어사진 만들기
-> kkma에서 명사라고 생각되는 것들만 토큰으로 만들어줌
tfidf.fit(X_train[:3])
tfidf.vocabulary_
5-2) VV, VA, NNG의 형태소만 토큰화
- 함수만들기
def myTokenizer2(text):
d = pd.DataFrame(kkma.pos(text), columns=['morph','tag'])
d.set_index('tag', inplace=True)
if ('VV' in d.index) | ('VA' in d.index) | ('NNG' in d.index):
labels = ['VV','VA','NNG']
return d.loc[d.index.intersection(labels)].dropna()['morph'].values
else :
return []- 3개의 문장 학습시켜서 단어사전 형태로 출력하기
tfidf = TfidfVectorizer(tokenizer = myTokenizer2)
tfidf.fit(X_train[:3])
tfidf.vocabulary_
6) pipeline 만들어서 학습시키기
- import 작업
from sklearn.pipeline import make_pipeline
from sklearn.svm import LinearSVC- pipeline을 통해 학습시키기 -> TfidfVectorizer , LinearSVC()
pipe = make_pipeline(TfidfVectorizer(tokenizer = myTokenizer2), LinearSVC())- 100개만 확인
pipe.fit(X_train[:100], y_train[:100])
- .steps : 결과물을 확인하기 위해 몇번째 단계에 어떤걸 사용했는지 확인하고 싶을 때 확인하는 함수
- pipeline에 연결된 tfidfvectorizer, linearsvc 각자 따로 확인할 수 있음
pipe.steps
--> pipeline에 연결되어있는 tfidf는 0행 1열에 있음
--> pipeline에 연결되어있는 svm는 1행 1열에 있음
- tfidf, svm 변수에 담아주기
pipe_tfidf = pipe.steps[0][1]
pipe_svm = pipe.steps[1][1]- pipe에 연결된 tfidf의 단어사전을 확인

- pipe_tfidf의 0 부정의 단어 확인
voc = pd.DataFrame(pipe_tfidf.vocabulary_.keys(),
index = pipe_tfidf.vocabulary_.values())
voc 
- index 기준으로 정렬해서 확인
voc.sort_index()
- Series형태로 확인
voc.sort_index()[0]# 토큰들과 가중치를 연결해서 각각의 토큰들이 긍정 / 부정에 얼마나 영향을 끼쳤는지 확인
# svm에 있는 가중치로 확인하기
- .T : dataframe에 넣기 위해 "ㅡ" > "ㅣ" 형태로 바꿔줌
pipe_svm.coef_.T
result = pd.DataFrame(pipe_svm.coef_.T, index = voc.sort_index()[0],
columns = ['w'])
result 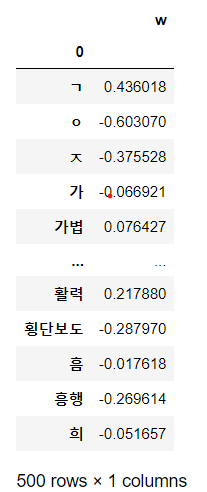
- w 가중치를 기준으로 정렬
- 부정적으로 판단하는데 영향을 많이 끼친 단어순
result.sort_values(by='w')
- 긍정적인 영향을 많이 끼친 단어들
result.sort_values(by='w', ascending = False)
위 과정은 스마트인재개발원 수업 내용입니다.
'+ 스마트인재개발원 +' 카테고리의 다른 글
| [스마트인재개발원] JSP&Servlet 정리(2), MVC (1) | 2021.07.04 |
|---|---|
| [스마트인재개발원] JSP & Servlet 정리 (1) | 2021.07.04 |
| [스마트인재개발원] [머신러닝] 영화 리뷰 분석하기 (1) | 2021.06.27 |
| [스마트인재개발원]210603 머신러닝 수업 정리 (0) | 2021.06.20 |
| [스마트인재개발원] [웹 크롤링] Gmarket Top 100 가져오기 (0) | 2021.06.20 |



