
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 광주인공지능학원
- CountVectorizer
- 자바
- 머신러닝
- Selenium
- 인공지능학원
- 딥러닝
- 크롤링
- 셀리니움
- DataFrame
- 과대적합
- jsp
- sellenium
- 파이썬
- permisision부여
- 활성화함수
- 데이터프레임
- 유투브크롤링
- servlet
- 토큰화
- tfidf
- relu
- 스마트인재개발원
- iris붓꽃
- 댓글분석
- 광주국비지원학원
- 인공지능
- python
- 과대적합제어
- 웹크롤링
- Today
- Total
+ Hello +
[스마트인재개발원] [머신러닝] 영화 리뷰 분석하기 본문

1. 문제정의
- 긍정리뷰, 부정리뷰를 구분하는 감성분석
- 긍정 / 부정에서 자주 사용되는 단어 확인
2. 데이터 수집
- largge movie dataset
# 파일 읽어오기
from sklearn.datasets import load_files
# Train 데이터 받아오기
train_data_url = 'aclImdb/train/'
reviews_train = load_files(train_data_url, shuffle = True)
# Test 데이터 받아오기
test_data_url = 'aclImdb/test'
reviews_test = load_files(test_data_url, shuffle = True)- reveiws_train의 키값 구하기
reviews_train.keys()
- 웹 상의 리뷰 데이터 하나 가져오기
> <br>태그 전처리하면서 빼야함
reviews_train['data'][0]
- 데이터는 배열 형태이므로 .vaolues_counts()안됨
> np.bincount로 개수 확인해주어야 함
reviews_train['target']

- 전체 train 데이터 개수는 2500개
len(reviews_train['data'])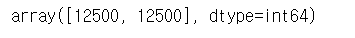
- 정답 데이터이 갯수 확인
- 값의 개수를 세어주는 함수 : np.bincount()
np.bincount(reviews_train['target'])
3. 데이터 전처리
- 일반 데이터 : 결측치 제거, 스케일링, 특성공학, 이상치 제거 등
- 텍스트 데이터
- 오탈자 제거
- 띄어쓰기 교정
- 이모티콘 수정
- 불필요한 글자 제거(불용어 제거, stop word)
- 데이터가 정형화 되어있다면 : 토큰화, 수치화
3-1) <br>태그 제거하기
text_train = [] # 비어있는 리스트 만들기
for txt in reviews_train['data']:
del_br = txt.replace(b"<br />", b" ") # br 태그를 공백으로 채움
text_train.append(del_br) # 값 채우기 - <br>태그 제거 -> 한줄로 요약할 수 있음 >> 리스트 내포
text_train = [txt.replace(b"<br />", b" ") for txt in reviews_train['data']]- <br>태그 잘 제거 되었는지 확인
text_train[0]
- 리스트 내포(br태그 제거) test 파일도 진행
text_test = [txt.replace(b"<br />", b" ") for txt in reviews_test['data']]- 토큰화 종류 : 단어단위, 글자단위, n-gram단위
- n-gram 단위 : n개의 연속된 단어를 하나로 취급하는 방법
- 토큰화 대상의 수가 크게 증가
- 토큰화 한 결과 수치로 만드는 방법 : 원핫 인코딩, BOW(단어모음), WORD VECTOR(단어 벡터)방법
- ex) 띄어쓰기 : 러시아 월드컵 --> 러시아, 월드컵
- ex) 2-gram 토큰 : 러시아 월드컵 --> 러시아, 월드컵, 러시아 월드컵
3-2) 토큰화
- BOW(Bag of Word) : 단어 토큰화, 단어사전 구축을 통한 수치화
- import
from sklearn.feature_extraction.text import CountVectorizer- test 예시문장을 통해 토큰화 해보기
testCV = CountVectorizer()
# test 예시 ~
test_txt = ['안녕하세요 저는 윤정은입니다.',
'지금은 머신러닝 수업 진행중입니다.',
'배가 조금 많이 고픕니다.',
'침대에 누워서 자고싶습니다.',
'마라탕 먹고싶습니다',
'오늘 날씨가 좋습니다!',
'놀러가고싶습니다.']
testCV.fit(test_txt) - 단어사전 : 각 단어에 인덱스가 자동으로 라벨링됨
testCV.vocabulary_

- 수치화(벡터화) : 숫자를 벡터로
testCV.transform(test_txt)
testCV.transform(test_txt).toarray()
* 영화 리뷰 데이터 토큰화, 수치화
movie_count = CountVectorizer()
movie_count.fit(text_train) - 단어 사전 길이 확인
len(movie_count.vocabulary_)- 수치화(벡터화)
# 문제 데이터
X_train = movie_count.transform(text_train)
X_test = movie_count.transform(text_test)# 정답 데이터
y_train = reviews_train['target']
y_test = reviews_test['target']
4. 탐색적 데이터 분석 (skip)
5. 모델 선택 및 하이퍼 파라미터 튜닝
5-1) svm -> linear_momel
- import
# svm
from sklearn.svm import LinearSVC
# 교차검증
from sklearn.model_selection import cross_val_score
svm = LinearSVC()- 교차검증
svm_result = cross_val_score(svm, X_train, y_train, cv = 5)
svm_result.mean()
6. 모델 학습
- 0은 부정, 1은 긍정으로 값이 나올 것
svm.fit(X_train, y_train)
7. 평가
- 1번 긍정, 2번 긍정, 3번 부정인 리뷰로 평가해보기
reviews = ["Wow. This is one of the most mind bending things in media. It makes Age Of Ultron better, it is very funny, the characters are so suprising and it also plays well into the MCU in other ways. The episode before the final one has great writing and the final showdowns are like watching an MCU film. This whole thing would be great as an MCU film, the way it plays. The return of people blipped also was interesting here and the story of Infinity War playing into the Vision storyline and how Wanda really just wanted more time with him. It is defismtly emotional and touching. Disney+ started off right with their first MCU tie in. The moral of this is that it seems to expose witchcraft rather then embrace it, which is good. (It might be exposing it). Jesus is our only hope.",
""" "We are an unusual couple, you know." "Oh, I don't think that was ever in question." Now, before I begin, there are many opinions of this show. Many fans and people just introduced to the MCU have strong opinions which has made this a very divided addition to the MCU. Critically, it's been praised and there aren't many people who don't like it. But with the unique approach, some have been upset for such the high ratings. What I'm trying to say is I ask you to bear with me and respect my opinion. If you differ with it, there's nothing you can do to change my mind. The absolute masterpiece that is WandaVision blends the style of classic sitcoms with the MCU, in which Wanda Maximoff and Vision - two super-powered beings living their ideal suburban lives - begin to suspect that everything is not as it seems. From that teaser at the Super Bowl (I believe) over a year ago, this had been something exciting to look forward to. Literally no one knew what this would be about going in, really. I refrained from all trailers to go in as blind as possible. What I got was more than what I could imagine. Trying something new is what I've hoped for in the MCU for a while. As much as I do love a good majority of their movies, there's a fixed setup for almost all. WandaVision is something totally different and just what we needed. Had this been a show outside of the MCU, I think it would still be brilliant. Each episode is designed to go through a different era of television. How they handled it worked incredibly well. There's not a way of trying to modernize these old sitcoms from the 1950s and so forth, so it's like a replication of classic television. The sets, costumes, and camera lens and moment are amazing at doing so. One of my favorite games while watching is trying to see what show this episode was mainly based on. Accomplishing this couldn't have been easy and I applaud them for how they managed to get the feel of each era perfectly. At the heart of this story are amazing performances. Elizabeth Olson hasn't had such an amazing display of acting since Martha Marcy May Marlene. So much emotion is put forth into Wanda that she is by far the most developed character in the MCU even if she came in late. There are some really heavy scenes and she portrayed those flawlessly. It doesn't feel much like watching a magical being, but we understand she's just another person in this world. Scene 8 showcases it all. Alongside her is Paul Bettany. With his character of Vision — a literal computer-god-being — it's hard to get complete range. He has such a good start with the series by delivering comedy. He's really funny in it (and Olsen too). Once the mystery starts to unfold, he builds more and more character until episode 5 when he unleashes his full capabilities. Never has Vision felt so human before. I'd also like to highlight Kathryn Hahn, because she's such an amazing actress. Playing the nosy-neighbor of Agnes must've been such a fun time. She takes up all the screen time she can get. I won't spoil a thing, but later on in the series she gets her moment — literally everyone's favorite moment — and you just love her even more. Teyonah Paris, Kat Dennings, and Randall Park also do well with their supporting roles. This is an ensemble piece for sure and the way they work off of each other shows dedication. It's hard to discuss so much without spoiling because certain things do need to be addressed, but I shall refrain. Story is where people have been divided. Some thought it took way too long to get into, and I just don't see why. It's a series, not a movie, so setup is much different. And if it were to have moved on quickly, the mystery element would've lost its momentum. Every episode has some sort of question leading up to the finale. That's where fan theories came in and caused even more disappointments. I support fan theories, but I don't base my expectation on the rest of the show. Even if I had some hopeful thoughts, I never expected them to show up later on. With expectation, you can only be disappointed. My suggestion is to not have anything in mind when going in. Questions kept building and that's what made this the most gripping show I had seen in such a long time. I would stay up till 2 a.m. for the release of the new episodes because I just had to know what would come next. With a series, there was more time to develop and think about plot and character. Most importantly, though, there was enough time to build upon the past episodes and make an enjoyable time for both the sitcom moments and the Marvel storyline. Sure, not every episode is as great as the one before or after. I don't think you'll ever find a show with each episode being perfect as ever. Take a highly regarded show like Breaking Bad. Many think of it as a perfect show, but it's not like they think every episode is perfect. To quote Steven Universe, one of my favorite shows, "if every pork chop were perfect, we wouldn't have hotdogs." If every episode were perfect, it wouldn't have that range that it has. I don't grade a show based on each episode, but rather as a whole. And throughout the duration of WandaVision, I had an absolute blast. Marvel, Matt Shakman, and the whole crew made something unforgettable. I believe this to be the greatest thing the MCU has given us. There will never be a show quite like WandaVision. Only a few shows have gotten my perfect rating, and this ranks among them. """ ,
''' ( SPOILERS) Absolute garbage and a waste of time. Full of plot twists that end up being nothing. Vision having holes in his body had nothing to do with the plot. Pietro having holes in his body had nothing to do with the plot. Pietro being from X'men was just a random coincidence. Also, every time a new male character walked into the show you knew he was either a wimp or evil. They even made pietros real last name "bohner" to make fun of manhood. Imagine if a female character everyone was stoked on turned out to be some random lady named "Vachina". Also, the physical vision just flew off for no reason, and digital vision never decided to tell wanda about his existence. Why? Lazy writing. Additionally at the end rhambeaou tells wanda "they will never know what you sacrificed". What the heck?! Like maybe apologize for trapping and tormenting these people every day for like a month. How on earth is wanda the victim or the "good-guy" in this show. She is literally a villain causing everyone pain, but it is "ok" because she did it out of a place of pain. Im sorry, almost all villains do evil out of a place of pain, that doesnt make it ok. Stupid, sexist show with bad plot that treats its audience like idiots. '''
]- 토큰화, 수치화
reviews_transform = movie_count.transform(reviews)- predict --> 1번 긍정, 2번 긍정, 3번 부정
svm.predict(reviews_transform)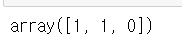
- 로지스틱 모델 사용
from sklearn.linear_model import LogisticRegression
logi = LogisticRegression()
logi.fit(X_train, y_train)
logi.predict_proba(reviews_transform)
- 불확실성에 대한 추정 -> 긍정, 긍정, 부정
- 숫자가 클수록 더 확실하다는 의미(양수 긍정, 음수 부정)
svm.decision_function(reviews_transform)
:: 정리 ::
데이터 전처리 -> 토큰화 (Countvectorizer) -> 모델(svm)
result_train -> text_train -> X_train (이름이 계속 변함)
- 데이터 전처리 -> 토큰화 + 모델
- 토큰화와 모델을 한번에 진행할 것임 > 파이프라인
5-2) pipeline (svm + linear_model)
- pipeline : 토큰화 + 모델학습을 동시에 진행
- import
from sklearn.pipeline import make_pipeline- 토큰화, 모델을 순서대로 명시해주어야함
pipe = make_pipeline(CountVectorizer(), LinearSVC())- 토큰화한 데이터를 알아서 linearSVC에 넣을 것임
- .fit(토큰화 하기 전의 데이터)
- text_train : 전처리한 데이터
pipe.fit(text_train, y_train)
- 예측
- 토큰화 하기 전 데이터 집어넣어야 예측이 진행됨
pipe.predict(reviews)
- CountVectorizer()의 파라미터 : 숫자를 기반을 토큰화
- min_df : 전체 문서 중에 등장해야하는 빈도의 최소치 설정
- max_df : 전체 문서 중에 등장해야하는 빈도의 최대치 설정
- ex) a, the처럼 너무 많이 나오는 단어들은 단어사전에 등록하지 않을것임
- n_gram
- grid Search 진행
- import
from sklearn.model_selection import GridSearchCV- 두개의 모델 동시에 그리드 서치할 수 있음 (CountVectorizer, LinearSVC)
- 파라미터 작성 : 모델이름_ _ 하이퍼파라미터
grid_params = {
'countvectorizer__min_df' : [3,5,10],
'countvectorizer__max_df' : [20000,22000,24000],
'countvectorizer__ngram_range' : [(1,2),(1,3),(2,2)],
'linearsvc__C' : [0.001,0.01,0.1,10,100]
}
grid = GridSearchCV(pipe, grid_params, cv=3, n_jobs=-1)6-2) 학습
grid.fit(text_train, y_train)- girdsearch 진행하고 나온 최고의 파라미터, 점수
print(grid.best_score_)
print(grid.best_params_):: tf-idf ::
- tf : 하나의 문서에서 단어가 등장하는 횟수
- idf : 전체 문서에서 단어가 등장하는 횟수(df)의 역수 # > 적은 문서에서 등장하는 단어일수록 값이 큼
- tf * idf = 적은 문서에서 등장하고, 등장하는 문서에서는 많이 쓰이는 단어를 중요한 단어라고 판단
tfidf = TfidfVectorizer()- 학습하기
tfidf.fit(test_txt)- 단어사전 확인
tfidf.vocabulary- 토큰화
tfidf.transform(test_txt).toarray()
- TfidfVectorizerk, linearSVC 이용해서 pipeline를 통해 결과값 예측
pipe = make_pipeline(TfidfVectorizer(), LinearSVC())- 학습하기
pipe.fit(text_train, y_train)- 예측하기
pipe.predict(reviews)
위 과정은 스마트인재개발원 수업 내용입니다.
'+ 스마트인재개발원 +' 카테고리의 다른 글
| [스마트인재개발원] JSP & Servlet 정리 (1) | 2021.07.04 |
|---|---|
| [스마트인재개발원] [머신러닝] 네이버 영화 리뷰 분석하기 (1) | 2021.06.27 |
| [스마트인재개발원]210603 머신러닝 수업 정리 (0) | 2021.06.20 |
| [스마트인재개발원] [웹 크롤링] Gmarket Top 100 가져오기 (0) | 2021.06.20 |
| [스마트인재개발원] [웹 크롤링] 유튜브 영상의 제목, 조회수 크롤링하기 (2) | 2021.06.09 |



