
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 활성화함수
- 인공지능학원
- 데이터프레임
- 유투브크롤링
- 자바
- CountVectorizer
- 크롤링
- 과대적합
- DataFrame
- jsp
- 댓글분석
- Selenium
- permisision부여
- tfidf
- relu
- 토큰화
- python
- 광주인공지능학원
- 머신러닝
- 셀리니움
- 과대적합제어
- 스마트인재개발원
- sellenium
- iris붓꽃
- 인공지능
- 딥러닝
- servlet
- 웹크롤링
- 광주국비지원학원
- 파이썬
Archives
- Today
- Total
+ Hello +
[스마트인재개발원] [웹 크롤링] 유튜브 영상의 제목, 조회수 크롤링하기 본문

1. import 작업하기
from selenium import webdriver as wb
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup as bs
import pandas as pd
import time2. 크롬 드라이버를 실행해서 유투브 화면 불러오기
driver = wb.Chrome()
url = ('https://www.youtube.com/results?search_query=%EB%94%A9%EA%B3%A0%EB%AE%A4%EC%A7%81')
driver.get(url)
3. 키보드의 PAGE_DOWN을 통해서 스크롤 내리기
- 페이지 정보가 담겨있는 body태그 찾기
- 키보드의 page_down을 통해서 스크롤 내리기
body = driver.find_element_by_tag_name('body')
body.send_keys(Keys.PAGE_DOWN)- 반복문을 통해 50번 스크롤 내리기
for i in range(1,51):
body.send_keys(Keys.PAGE_DOWN)
time.sleep(0.5)4. soup을 통해 데이터 가져오기
- bs(page정보 가지고 있는 주체, 'lxml')
soup = bs(driver.page_source, 'lxml')5. 영상 제목 가져오기
title =soup.select('a#video-title')
# 영상 제목만 전체 조회
for i in title:
print(i.text.strip())6. 조회수 가져오기
soup.select('span.style-scope.ytd-video-meta-block')- span class 명이 같은 자식이 2개 (구분자 존재하지 않음)
> 조회수, 날짜가 같이 뜸
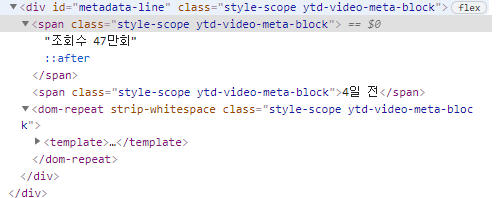

* 조회수만 데려오기
1) 부모 태그의 아이디를 통해 첫 번째 span 데려오기
- nth-child():몇 번째 자식인지
soup.select('div#metadata-line > span:nth-child(1)')
2) 검사 > 마우스 우클릭 > copy > copy selector > #metadata-line > span:nth-child(1)
7. 데이터 프레임 작성
- title, view 리스트에 값을 하나씩 넣어주기 : .append
title_list = []
view_list = []
for i in range(len(title)):
title_list.append(title[i].text.strip())
view_list.append(view[i].text.strip())
print(title_list)
print(view_list)info = {'제목':title_list, '영상길이':time_list}
pd.DataFrame(info)
위 과정은 스마트인재개발원 수업 내용입니다.
'+ 스마트인재개발원 +' 카테고리의 다른 글
| [스마트인재개발원]210603 머신러닝 수업 정리 (0) | 2021.06.20 |
|---|---|
| [스마트인재개발원] [웹 크롤링] Gmarket Top 100 가져오기 (0) | 2021.06.20 |
| [스마트인재개발원][웹 크롤링] Selenium 모듈 | 한솥 도시락 메뉴, 가격 데이터 프레임만들기 (0) | 2021.06.08 |
| [스마트인재개발원] [웹 크롤링] 멜론 TOP 100 수집하기 (0) | 2021.06.05 |
| [스마트인재개발원] [웹크롤링] Request, BeautifulSoup 사용하기, 네이버 기사 제목 크롤링하기 (0) | 2021.06.04 |
'+ 스마트인재개발원 +' Related Articles
more




Comments