
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 셀리니움
- 딥러닝
- 데이터프레임
- servlet
- 과대적합
- jsp
- 활성화함수
- 웹크롤링
- iris붓꽃
- 댓글분석
- 자바
- python
- Selenium
- 스마트인재개발원
- tfidf
- 크롤링
- relu
- 토큰화
- sellenium
- 머신러닝
- 파이썬
- 인공지능
- 인공지능학원
- DataFrame
- 과대적합제어
- 유투브크롤링
- 광주국비지원학원
- 광주인공지능학원
- permisision부여
- CountVectorizer
- Today
- Total
+ Hello +
[스마트인재개발원] [웹크롤링] Request, BeautifulSoup 사용하기, 네이버 기사 제목 크롤링하기 본문
[스마트인재개발원] [웹크롤링] Request, BeautifulSoup 사용하기, 네이버 기사 제목 크롤링하기
journeyee 2021. 6. 4. 13:30
Request
- 페이지 정보를 요청할 때 사용하는 라이브러리
:: Request ::
# Import 작업 해주기 : import requets as req
# 요청을 도와주는 라이브러리 : req.get
# 요청한 페이지의 정보 보기 : req.text
먼저 import 작업해주기

- 네이버 페이지 요청하기 : req.get('ulr')
(http:// 꼭 작성해주기, https://는 보안)

- response[200] : 페이지를 잘 불러왔다는 표시
- 다시 res 변수에 담아주기

- 요청한 페이지의 정보 확인 : .text

Melon 홈페이지에서 정보 가지고 오기
1. 멜론 페이지 요청하기
- 네이버처럼 https://멜론 을 입력하면 Response [406] 이 뜬다
- Response[406] : 컴퓨터가 아닌 사용자가 접속하는 걸로 속이는 작업 필요!

<User-Agent 찾는 방법>
- 멜론 사이트 + F12
- 1번 Network 클릭
- 2번 type이 document인 것 찾아 클릭하기
- 3번 User-Agent 부분 복사하기

- 딕셔너리 구조로 만들어 변수에 담아주기 {'key':'value'}

- req.get('멜론 url', headers=h)
- header는 고정값 = h는 user-agent 변수

2. 요청한 페이지의 정보 보기 : res. text

:: Beautifulsoup ::
- 가져온 데이터에서 내가 필요한 정보들만 추출해주는 라이브러리
- bs4 라는 폴더에 있으므로 from bs4 사용하기
네이버에서 블로그라는 글자 가져오기

1. 네이버 페이지 요청하기 >> request

2. 내가 필요한 정보만 추출하기 >> BeautifulSoup
- BeautifulSoup import 작업
- bs(어떤 데이터, 'lxml' : 어떻게 처리)
- 'lxml' : 파싱방법

3. 내가 원하는 정보 찾아오기 >> .find_all()
- 내가 가지고 온 데이터에서 a태그 중 클래스 명 nav만 가져오기
- Class : 예약어(초록색_ >> Class_로 명시(_만 가능)
- .find_all() : 모든 데이터 찾아오기
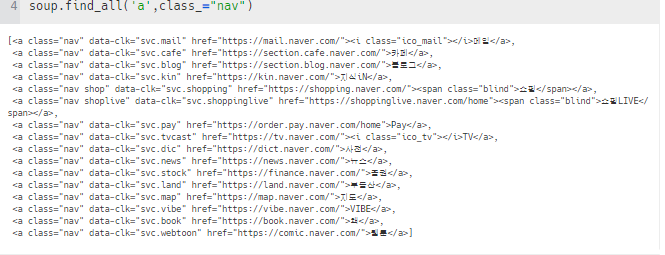
[] 리스트 형태로 가져옴 > class='nav'인 값이 여러 개이기 때문에 리스트 형태로 출력 됨
4. 가지고 온 데이터에서 순수하게 글자만 추출하기 : .text

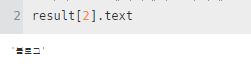

5. For문(리스트[]형태)을 사용하여 전체 데이터 조회하기

네이버 뉴스 타이틀만 가져오기
1. requestsm beautifulsoup > import 작업
2. 네이버 페이지 불러오기

3. 필요한 정보 전부 찾아오기 : find_all()

- 기자 타이틀의 태그, id, class 명 확인하기
- soup.find_all('a태그', class_='클래스명')

본 수업은 스마트인재개발원에서 진행되었습니다.
http://www.smhrd.or.kr/
스마트인재개발원
4차산업혁명시대를 선도하는 빅데이터, 인공지능, 사물인터넷 전문 '0원' 취업연계교육기관
www.smhrd.or.kr
'+ 스마트인재개발원 +' 카테고리의 다른 글
| [스마트인재개발원] [웹 크롤링] 유튜브 영상의 제목, 조회수 크롤링하기 (2) | 2021.06.09 |
|---|---|
| [스마트인재개발원][웹 크롤링] Selenium 모듈 | 한솥 도시락 메뉴, 가격 데이터 프레임만들기 (0) | 2021.06.08 |
| [스마트인재개발원] [웹 크롤링] 멜론 TOP 100 수집하기 (0) | 2021.06.05 |
| 0515 DB create table, alter table (0) | 2021.05.30 |
| [자바 페스티벌] 01~05번 문제 풀이 (0) | 2021.05.09 |



